




透過 AI 成生技術 將影像壓縮至 0.01%
🔴 Update︰大家好像誤會了,或者不知道什麼是關鍵影格(Keyframe)。關鍵影格是原片中的真實畫面,只需要每秒二至三格的關鍵影格,就能避免出現運動錯覺,其餘需要補滿的畫格就稱作「中間格」(in-betweens)。
AI 生成是從兩張「關鍵影格」之間,自動計算並生成中間的過渡影格,因此影片不可能和真實影像有太大差距。舉例來說,如果以每秒一張關鍵影格,而影片是 30fps,AI 會先分析兩張關鍵影像,並按照描述語、資訊與運動特徵去填補餘下的 29 格,所以每一秒都會有一幀真實的畫面,不會全部內容都是假的;影像仍然要根據關鍵影格的內容去生成,而語義資訊與運動特徵只是用來提高準確度。
關鍵影格密度是可調的,例如每秒 5 張關鍵影格,影片的真實度就會大大提升;甚至每秒 10 張關鍵影格,已經能節省大量資料。大家可以把它想像成 DLSS 的影片版,它只是補幀而已,不可能變成另一隻 Game 啦。
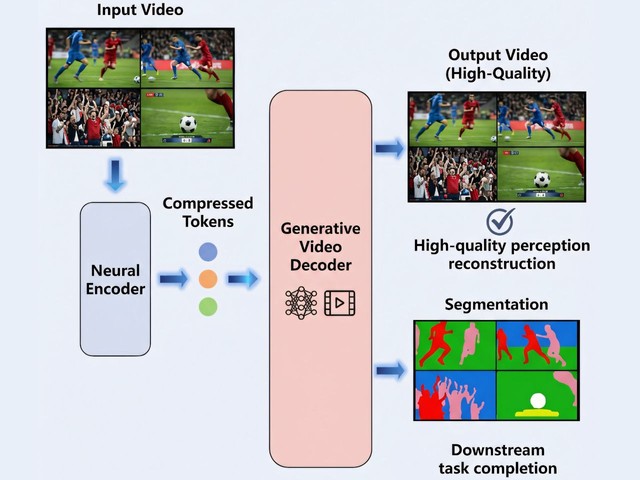
此外,有人說這不是壓縮技術。上面的原理圖寫著 Compressed Tokens,它是把關鍵影格、影像描述的語義資訊與運動特徵進行壓縮;雖然不是全像素壓縮,但關鍵影格的像素仍然需要壓縮和解壓。
應該是小編寫得不好,讓大家誤會了。😣😣😣
【生成式影像壓縮 ... 😱】TeleAI 近日發布全新 GVC 格式影像壓縮技術。有別於傳統影像壓縮技術專注於像素層級重建原始影像訊號,GVC 透過生成式 AI 模型,可將 1GB 原影片壓至僅 100KB,實現 0.005 bpp 的超低影像壓縮率。
根據 GVC 格式影像壓縮技術白皮書,這是一種新穎的視訊壓縮方法,透過神經網路編碼器處理輸入影像產生壓縮令牌,當中包括壓縮關鍵影格,以及擷取影像描述語義資訊與運動特徵,實現接近 0.01% 的極限壓縮率。
GVC 的影像串流資料或檔案,會透過生成式 AI 影像解碼器,根據影像描述語義資訊與運動特徵,將關鍵影格的圖片延展為在視覺上可信的影片內容。
有別於傳統影像壓縮技術(例如 H.265/AV1),其重點在於重建原始影像訊號的精確像素,因此難以避免需要大量像素資料;GVC 的目標是把實用性置於精確重建之上,傳輸過程中不會保留每個像素細節,而是選擇與任務最相關的資訊,從最少的輸入合成高品質且新穎的視訊內容,令所需傳輸的資訊量大幅減少。
GVC 格式影像壓縮技術曾在遠洋衛星環境進行測試,只需每秒一至兩張關鍵影格,便能高解析度、流暢地直播足球比賽,所需頻寬僅為 HEVC 的六分之一。當然,關鍵影格越多、原始影像品質越高,GVC 的影像生成精確度會進一步提升,需要在品質與壓縮比之間作出權衡。
資料來源:
